快慢指针寻找链表中的环
在做Find the Duplicate Number的时候,看到一个非常有趣的算法。这个算法可以用$O(n)$的复杂度来寻找链表(有向图)中的环的起始点。
¶问题描述
问题要求在$n+1$个数中寻找重复的数,其中数是$[1, n]$中的整数。由此很容易证明序列中一定会有重复的数。
题目有四个限制条件,限制了常用的减少复杂度的方法:
- 不能修改原数据。(不能使用$O(n\log n)$的排序算法进行预处理)
- 只能使用$O(1)$的空间。(不能使用哈希表)
- 计算复杂度小于$O(n^2)$。(不能穷举)
- 只有一个重复的数字,但是重复的次数可能不止一次。(不能使用数学公式直接得出)
在限制之下,这个看似简单的问题的解法就变得很少了。一种方法是把传入的数组看作是邻接数组。此时就可以将问题看作是在链表(有向图)中寻找环的问题。
¶深度优先搜索(DFS)
在有向图中寻找环,首先想到的算法是深度优先搜索(DFS),但是由于要标记访问过的节点,需要$O(n)$的空间复杂度,不符合本题的限制。
¶快慢指针法
在无法使用DFS的情况下,可以使用双指针去解决寻找链表中的环的问题。问题转化非常巧妙。由于算法细节乍看难以理解,这里先展示算法代码:
1 | class Solution: |
¶算法思想
整个算法包含两个部分,第一部分在寻找环的位置,第二部分是寻找所在环的入口点。而这个入口点就是我们要寻找的重复的数。以[1, 3, 4 ,2, 2]为例,用链表可以表示为下图。
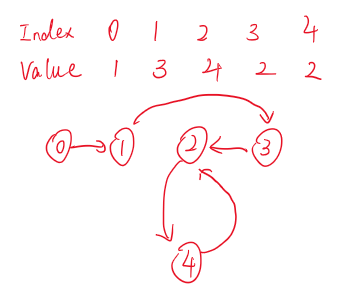
很显然因为重复的数会有多条边同时指向它,因此重复的数就是链表中环的起始点。
算法的第一部分是使用两个指针,一个快指针fastTag,一个慢指针slowTag。fastTag一次前进两步,slowTag一次前进一步。直到两者相等停止。原理很简单,假设环是一个跑道,当两个不同速度的运动员在环中跑步,不限跑动距离的情况下,跑的慢的运动员总会被跑的快的运动员“套圈”。被套圈的位置必然在环中。这个位置是我们算法的一个中间结果,记为$m$。
第二部分是算法难以理解的部分,我们将其中的一个指针,如fastTag重新放到起始点0。并在循环中同时将每一个指针的位置向前移动一个位置。到它们相遇的时候,相遇点就是环的起始位置。用数学可以证明这一点。
¶第二次循环的相遇点是环起始点的证明
设起点0到第一次循环的相遇点$m$的距离为$d$。环的长度为$c$。显然,慢指针移动的距离为$d_s = d$。快指针移动速度是慢指针的两倍,因此移动的距离为$d_f = 2d_s = 2d=d+nc$,其中$n$为正整数。整理有$d=nc$。设起始点到环的入口点的距离为$l$,入口点到第一次循环相遇点的距离为$d_m$。有$d=l+d_m$。将$d=nc$带入,有$nc=l+d_m$。整理有$l=(n-1)c+(c-d_m)$。因此,从起点开始的指针前进$l$步的同时,从中间位置出发的指针会回到环的起始点。
¶总结
这套算法的时间复杂度为$O(n)$,空间复杂度为$O(1)$,符合题目的限制。这套算法精彩的地方在使用两个速度不同的指针在环中相遇做文章。实在是非常聪明的想法。